
1. Introduction to OpenLDAP Directory Services
This document describes how to build, configure, and operate OpenLDAP Software to provide directory services. This includes details on how to configure and run the Standalone
1.1. What is a directory service?
A directory is a specialized database specifically designed for searching and browsing, in additional to supporting basic lookup and update functions.
Note: A directory is defined by some as merely a database optimized for read access. This definition, at best, is overly simplistic.
Directories tend to contain descriptive, attribute-based information and support sophisticated filtering capabilities. Directories generally do not support complicated transaction or roll-back schemes found in database management systems designed for handling high-volume complex updates. Directory updates are typically simple all-or-nothing changes, if they are allowed at all. Directories are generally tuned to give quick response to high-volume lookup or search operations. They may have the ability to replicate information widely in order to increase availability and reliability, while reducing response time. When directory information is replicated, temporary inconsistencies between the consumers may be okay, as long as inconsistencies are resolved in a timely manner.
There are many different ways to provide a directory service. Different methods allow different kinds of information to be stored in the directory, place different requirements on how that information can be referenced, queried and updated, how it is protected from unauthorized access, etc. Some directory services are local, providing service to a restricted context (e.g., the finger service on a single machine). Other services are global, providing service to a much broader context (e.g., the entire Internet). Global services are usually distributed, meaning that the data they contain is spread across many machines, all of which cooperate to provide the directory service. Typically a global service defines a uniform namespace which gives the same view of the data no matter where you are in relation to the data itself.
A web directory, such as provided by the Curlie Project <https://curlie.org>, is a good example of a directory service. These services catalog web pages and are specifically designed to support browsing and searching.
While some consider the Internet
1.2. What is LDAP?
This section gives an overview of LDAP from a user's perspective.
What kind of information can be stored in the directory? The LDAP information model is based on entries. An entry is a collection of attributes that has a globally-unique
How is the information arranged? In LDAP, directory entries are arranged in a hierarchical tree-like structure. Traditionally, this structure reflected the geographic and/or organizational boundaries. Entries representing countries appear at the top of the tree. Below them are entries representing states and national organizations. Below them might be entries representing organizational units, people, printers, documents, or just about anything else you can think of. Figure 1.1 shows an example LDAP directory tree using traditional naming.
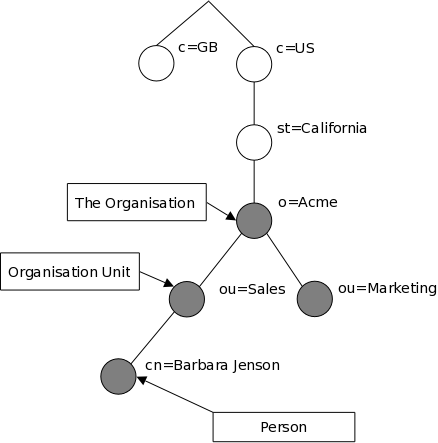
Figure 1.1: LDAP directory tree (traditional naming)
The tree may also be arranged based upon Internet domain names. This naming approach is becoming increasing popular as it allows for directory services to be located using the DNS. Figure 1.2 shows an example LDAP directory tree using domain-based naming.
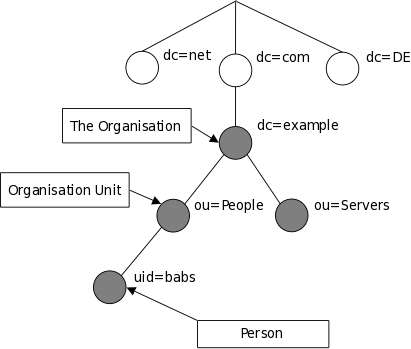
Figure 1.2: LDAP directory tree (Internet naming)
In addition, LDAP allows you to control which attributes are required and allowed in an entry through the use of a special attribute called objectClass. The values of the objectClass attribute determine the schema rules the entry must obey.
How is the information referenced? An entry is referenced by its distinguished name, which is constructed by taking the name of the entry itself (called the
How is the information accessed? LDAP defines operations for interrogating and updating the directory. Operations are provided for adding and deleting an entry from the directory, changing an existing entry, and changing the name of an entry. Most of the time, though, LDAP is used to search for information in the directory. The LDAP search operation allows some portion of the directory to be searched for entries that match some criteria specified by a search filter. Information can be requested from each entry that matches the criteria.
For example, you might want to search the entire directory subtree at and below dc=example,dc=com for people with the name Barbara Jensen, retrieving the email address of each entry found. LDAP lets you do this easily. Or you might want to search the entries directly below the st=California,c=US entry for organizations with the string Acme in their name, and that have a fax number. LDAP lets you do this too. The next section describes in more detail what you can do with LDAP and how it might be useful to you.
How is the information protected from unauthorized access? Some directory services provide no protection, allowing anyone to see the information. LDAP provides a mechanism for a client to authenticate, or prove its identity to a directory server, paving the way for rich access control to protect the information the server contains. LDAP also supports data security (integrity and confidentiality) services.
1.3. When should I use LDAP?
This is a very good question. In general, you should use a Directory server when you require data to be centrally managed, stored and accessible via standards based methods.
Some common examples found throughout the industry are, but not limited to:
- Machine Authentication
- User Authentication
- User/System Groups
- Address book
- Organization Representation
- Asset Tracking
- Telephony Information Store
- User resource management
- E-mail address lookups
- Application Configuration store
- PBX Configuration store
- etc.....
There are various Distributed Schema Files that are standards based, but you can always create your own Schema Specification.
There are always new ways to use a Directory and apply LDAP principles to address certain problems, therefore there is no simple answer to this question.
If in doubt, join the general LDAP forum for non-commercial discussions and information relating to LDAP at: http://www.umich.edu/~dirsvcs/ldap/mailinglist.html and ask
1.4. When should I not use LDAP?
When you start finding yourself bending the directory to do what you require, maybe a redesign is needed. Or if you only require one application to use and manipulate your data (for discussion of LDAP vs RDBMS, please read the LDAP vs RDBMS section).
It will become obvious when LDAP is the right tool for the job.
1.5. How does LDAP work?
LDAP utilizes a client-server model. One or more LDAP servers contain the data making up the directory information tree (
1.6. What about X.500?
Technically,
While LDAP is still used to access X.500 directory service via gateways, LDAP is now more commonly directly implemented in X.500 servers.
The Standalone LDAP Daemon, or slapd(8), can be viewed as a lightweight X.500 directory server. That is, it does not implement the X.500's DAP nor does it support the complete X.500 models.
If you are already running a X.500 DAP service and you want to continue to do so, you can probably stop reading this guide. This guide is all about running LDAP via slapd(8), without running X.500 DAP. If you are not running X.500 DAP, want to stop running X.500 DAP, or have no immediate plans to run X.500 DAP, read on.
It is possible to replicate data from an LDAP directory server to a X.500 DAP
1.7. What is the difference between LDAPv2 and LDAPv3?
LDAPv3 was developed in the late 1990's to replace LDAPv2. LDAPv3 adds the following features to LDAP:
- Strong authentication and data security services via
SASL - Certificate authentication and data security services via
TLS (SSL) - Internationalization through the use of Unicode
- Referrals and Continuations
- Schema Discovery
- Extensibility (controls, extended operations, and more)
LDAPv2 is historic (RFC3494). As most so-called LDAPv2 implementations (including slapd(8)) do not conform to the LDAPv2 technical specification, interoperability amongst implementations claiming LDAPv2 support is limited. As LDAPv2 differs significantly from LDAPv3, deploying both LDAPv2 and LDAPv3 simultaneously is quite problematic. LDAPv2 should be avoided. LDAPv2 is disabled by default.
1.8. LDAP vs RDBMS
This question is raised many times, in different forms. The most common, however, is: Why doesn't OpenLDAP use a relational database management system (RDBMS) instead of an embedded key/value store like LMDB? In general, expecting that the sophisticated algorithms implemented by commercial-grade RDBMS would make OpenLDAP be faster or somehow better and, at the same time, permitting sharing of data with other applications.
The short answer is that use of an embedded database and custom indexing system allows OpenLDAP to provide greater performance and scalability without loss of reliability. OpenLDAP uses
Now for the long answer. We are all confronted all the time with the choice RDBMSes vs. directories. It is a hard choice and no simple answer exists.
It is tempting to think that having a RDBMS backend to the directory solves all problems. However, it is a pig. This is because the data models are very different. Representing directory data with a relational database is going to require splitting data into multiple tables.
Think for a moment about the person objectclass. Its definition requires attribute types objectclass, sn and cn and allows attribute types userPassword, telephoneNumber, seeAlso and description. All of these attributes are multivalued, so a normalization requires putting each attribute type in a separate table.
Now you have to decide on appropriate keys for those tables. The primary key might be a combination of the DN, but this becomes rather inefficient on most database implementations.
The big problem now is that accessing data from one entry requires seeking on different disk areas. On some applications this may be OK but in many applications performance suffers.
The only attribute types that can be put in the main table entry are those that are mandatory and single-value. You may add also the optional single-valued attributes and set them to NULL or something if not present.
But wait, the entry can have multiple objectclasses and they are organized in an inheritance hierarchy. An entry of objectclass organizationalPerson now has the attributes from person plus a few others and some formerly optional attribute types are now mandatory.
What to do? Should we have different tables for the different objectclasses? This way the person would have an entry on the person table, another on organizationalPerson, etc. Or should we get rid of person and put everything on the second table?
But what do we do with a filter like (cn=*) where cn is an attribute type that appears in many, many objectclasses. Should we search all possible tables for matching entries? Not very attractive.
Once this point is reached, three approaches come to mind. One is to do full normalization so that each attribute type, no matter what, has its own separate table. The simplistic approach where the DN is part of the primary key is extremely wasteful, and calls for an approach where the entry has a unique numeric id that is used instead for the keys and a main table that maps DNs to ids. The approach, anyway, is very inefficient when several attribute types from one or more entries are requested. Such a database, though cumbersomely, can be managed from SQL applications.
The second approach is to put the whole entry as a blob in a table shared by all entries regardless of the objectclass and have additional tables that act as indices for the first table. Index tables are not database indices, but are fully managed by the LDAP server-side implementation. However, the database becomes unusable from SQL. And, thus, a fully fledged database system provides little or no advantage. The full generality of the database is unneeded. Much better to use something light and fast, like
A completely different way to see this is to give up any hopes of implementing the directory data model. In this case, LDAP is used as an access protocol to data that provides only superficially the directory data model. For instance, it may be read only or, where updates are allowed, restrictions are applied, such as making single-value attribute types that would allow for multiple values. Or the impossibility to add new objectclasses to an existing entry or remove one of those present. The restrictions span the range from allowed restrictions (that might be elsewhere the result of access control) to outright violations of the data model. It can be, however, a method to provide LDAP access to preexisting data that is used by other applications. But in the understanding that we don't really have a "directory".
Existing commercial LDAP server implementations that use a relational database are either from the first kind or the third. I don't know of any implementation that uses a relational database to do inefficiently what LMDB does efficiently. For those who are interested in "third way" (exposing EXISTING data from RDBMS as LDAP tree, having some limitations compared to classic LDAP model, but making it possible to interoperate between LDAP and SQL applications):
OpenLDAP includes back-sql - the backend that makes it possible. It uses ODBC + additional metainformation about translating LDAP queries to SQL queries in your RDBMS schema, providing different levels of access - from read-only to full access depending on RDBMS you use, and your schema.
For more information on concept and limitations, see slapd-sql(5) man page, or the Backends section. There are also several examples for several RDBMSes in back-sql/rdbms_depend/* subdirectories.
1.9. What is slapd and what can it do?
slapd(8) is an LDAP directory server that runs on many different platforms. You can use it to provide a directory service of your very own. Your directory can contain pretty much anything you want to put in it. You can connect it to the global LDAP directory service, or run a service all by yourself. Some of slapd's more interesting features and capabilities include:
LDAPv3: slapd implements version 3 of
Topology control: slapd can be configured to restrict access at the socket layer based upon network topology information. This feature utilizes TCP wrappers.
Access control: slapd provides a rich and powerful access control facility, allowing you to control access to the information in your database(s). You can control access to entries based on LDAP authorization information,
Internationalization: slapd supports Unicode and language tags.
Choice of database backends: slapd comes with a variety of different database backends you can choose from. They include
Multiple database instances: slapd can be configured to serve multiple databases at the same time. This means that a single slapd server can respond to requests for many logically different portions of the LDAP tree, using the same or different database backends.
Generic modules API: If you require even more customization, slapd lets you write your own modules easily. slapd consists of two distinct parts: a front end that handles protocol communication with LDAP clients; and modules which handle specific tasks such as database operations. Because these two pieces communicate via a well-defined
Threads: slapd is threaded for high performance. A single multi-threaded slapd process handles all incoming requests using a pool of threads. This reduces the amount of system overhead required while providing high performance.
Replication: slapd can be configured to maintain shadow copies of directory information. This single-provider/multiple-consumer replication scheme is vital in high-volume environments where a single slapd installation just doesn't provide the necessary availability or reliability. For extremely demanding environments where a single point of failure is not acceptable, multi-provider replication is also available. With multi-provider replication two or more nodes can accept write operations allowing for redundancy at the provider level.
slapd includes support for LDAP Sync-based replication.
Proxy Cache: slapd can be configured as a caching LDAP proxy service.
Configuration: slapd is highly configurable through a single configuration file which allows you to change just about everything you'd ever want to change. Configuration options have reasonable defaults, making your job much easier. Configuration can also be performed dynamically using LDAP itself, which greatly improves manageability.
1.10. What is lloadd and what can it do?
lloadd(8) is a daemon that provides an LDAPv3 load balancer service. It is responsible for distributing requests across a set of slapd instances.
See the Load Balancing with lloadd chapter for information about how to configure and run lloadd(8).
Alternatively, the load balancer can run as a module embedded inside of slapd. This is also described in the Load Balancing with lloadd chapter.